及遇智悦
数据和智能驱动的精准医学
在生物医学研究领域,海量的信息和知识被储存在学术论文、教科书、临床指南等文献资料中。这种非结构化的知识表达形式限制了信息的整合与再利用效率。近年来,得益于如GPT和BERT等预训练大型语言模型的卓越语言理解能力,我们得以高效地构建结构化的知识库。
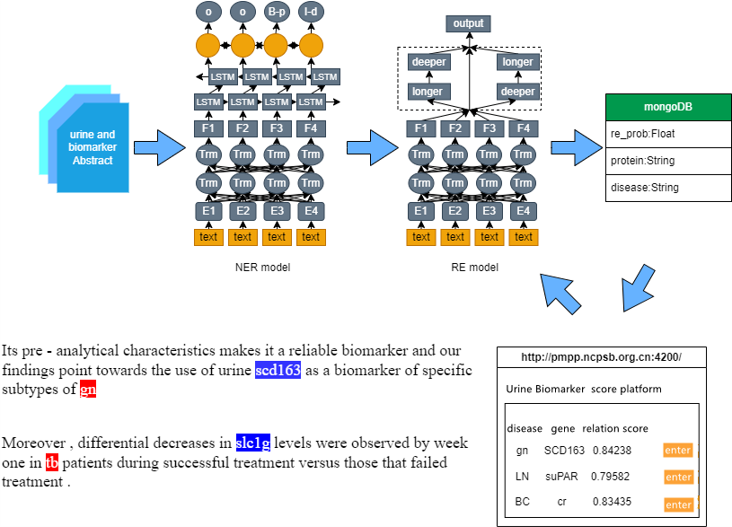
我们与重庆邮电大学携手合作,开发了BiomarkerExtractor系统,包括基于大型语言模型的先进文本挖掘算法和人工审核评价模型结果的众包平台。我们将其应用于提取文献报道的尿液样本中潜在的蛋白质和代谢生物标志物信息。
我们正在致力于将新构建的知识库与知识图谱整合,打造领域专门知识图谱。探索基于深度的知识整合的新知识发现路径,以推动新生物标志物的发现。
BiomarkerExtractor包括一个BioBERT-BiLSTM-CRF模型,用于识别命名实体,以及一个BioBERT-FAM模型,用于提取生物标志物与疾病之间的关系。提取到的信息存储于mongoDB,通过一个众包打分平台进行人工评价。
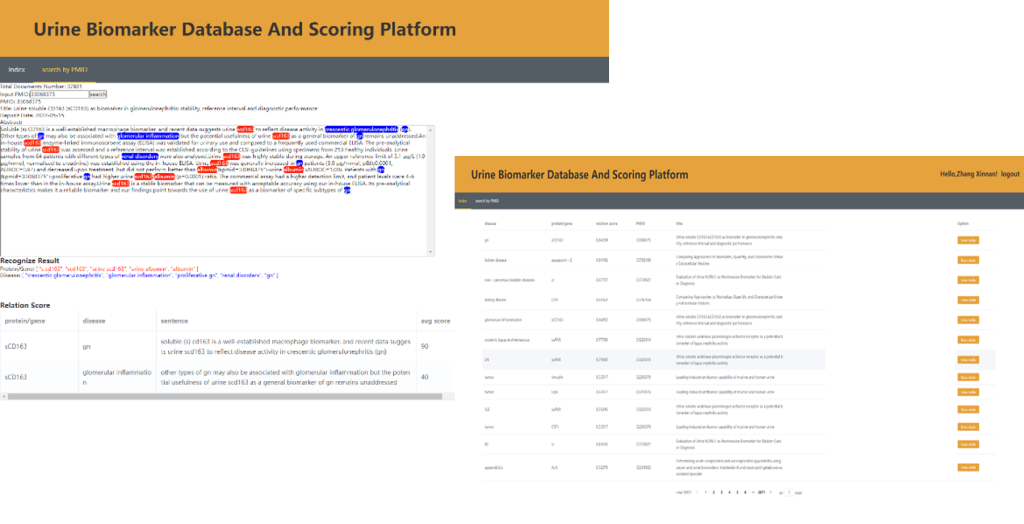
机器学习模型不可避免地产生错误。为了构建高质量的知识库,我们开发了基于众包理念的在线结果可视化平台,便于对机器学习结果进行评价和证据溯源。
人工验证后的机器学习将用于模型的迭代训练,进一步提升模型的准确度。